TF-IDF (Term Frequency & Inverse Document Frequency)
TF-IDF stands for Term Frequency and Inverse Document Frequency. This method is better than the BoW (Bag of Words) because BoW gives the number of occurance through numeric vector of each word in the document but TF-IDF gives the importance of each word throuogh numeric value in the document.
Let us go through all the steps with an example:
Document 1: Aman and Anil are stressed.
Document 2: Aman went to a therapist.
Document 3: Anil went to download a health chatbot.
Term Frequency: It is the frequency of a word in one document. It can be found from document vector table.
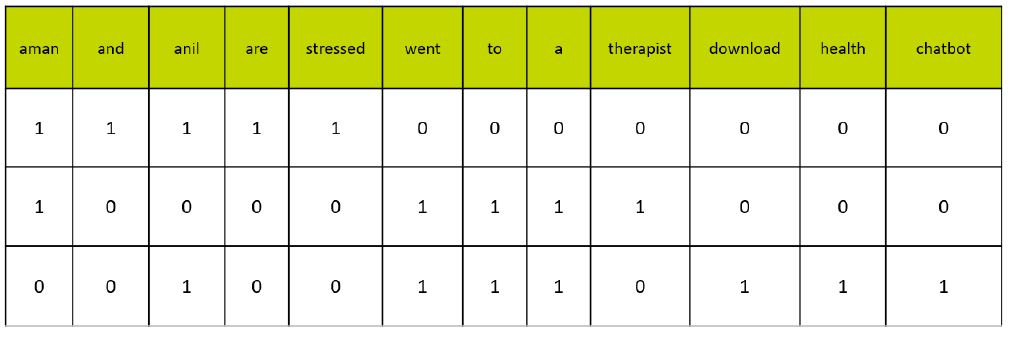
Document Frequency: It is the number of documents in which the word occurs irrespective of how many times it has occured in thosedocuments.
Inverse Document Frequency: It is obtained when documents frequency is in denominator and the total number of documents is the numerator.
Applications of TF-IDF
- Document Classification: It helps in the classification of the documents scattered in the internet based on their types, categories etc.
- Topic modelling: It helps in predicting the topics of the corpus.
- Information retrieval System: It searches the corpus and retrieves the information based on the most relevant searches.
NLTK (Natural Language ToolKit)
Natural Language Toolkit (NLTK) is one of the leading open-source NLP toolkit made up of Python libraries and used for building Python programs that can work with human language data.