Concept of Natural Language processing (NLP)
Humans interact with each other very easily. But for computers, our languages are very complex as it can understand only binary language i.e. '0' and '1'. Therefore, we need to convert human language into binary numbers.
Text Normalisation: In Text Normalization, we undergo several steps to normalize the text to a lower level. It helps in cleaning up the textual data in such a way that it comes down to a level where its complexity is lower than the actual data. Text Normalisation is working on Corpus.
Corpus: In Text Normalization, A corpus is a large and structured set of machine-readable texts that have been produced in a natural communicative setting.
A corpus can be defined as a collection of entire text of all documents in a dataset.
Now, Let us take a look at the steps:
- Sentence Segmentation
- Tokenisation
- Removing Stopwords, Special Characters and Numbers
- Converting text to a common case
- Stemming/Lemmatization
1. Sentence Segmentation
In sentence segmentation, the whole corpus is divided into sentences.So now, the whole corpus gets reduced to sentences.
For example: Let us look a Corpus below-
Raj and Vijay are best friends. They play together with other friends. Raj likes to play football but Vijay prefers to play online games. Raj wants to be a footballer. Vijay wants to become an online gamer.
Now, the sentence segmentation is -
- Raj and Vijay are best friends.
- They play together with other friends.
- Raj likes to play football but Vijay prefers to play online games.
- Raj wants to be a footballer.
- Vijay wants to become an online gamer.
2. Tokenisation
After segmenting the sentences, each sentence is then further divided into tokens.
Token: It may be refers to any word or number or special character occurring in a sentence.
Under tokenisation, every word, number and special character is considered separately and each of them is now a separate token.
For example: Let us consider the above Corpus.
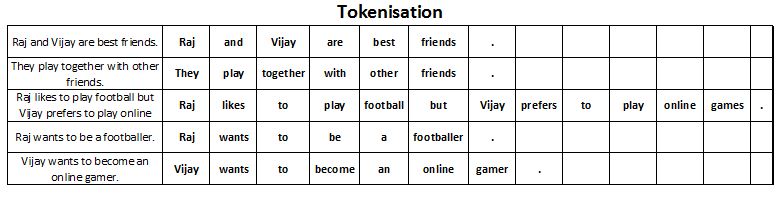
3. Removing Stopwords, Special Characters and Numbers
In this step, the tokens which are not necessary are removed from the token list.
Stopwords: Stopwords are the words which occur very frequently in the corpus but do not add any value to it. eg. - a, an, and, are, as, for, it, is, into, in, if, on, or, such, the, there, to etc. Hence, to make it easier for the computer to focus on meaningful terms, these words are removed.
For example: Let us consider the above Corpus.
Here, stopwords and, are, to, a, an will be removed. Also, symbol like '.' will be removed.
4. Converting text to a common case
After the stopwords removal, we convert the whole text into a similar case, preferably lower case (small letters).
This ensures that the case-sensitivity of the machine does not consider same words as different just because of different cases.
For example: "Raj and Vijay, raj And vijay, RAJ AND VIJAY" may be consider as different, therefore, convert it into lower case as "raj and vijay".
5. Stemming/Lemmatization
Stemming: Stemming is the process in which the affixes of words are removed and the words are converted to their base form.
Sometimes, in stemming, the stemmed words (words which are we get after removing the affixes) might not be meaningful.
For example:
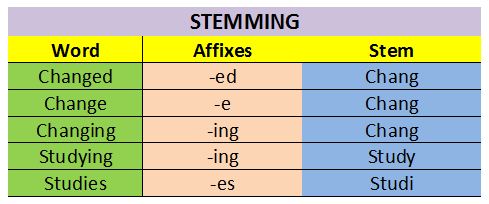
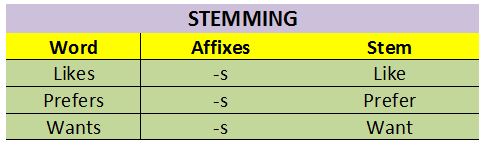
In the above Corpus, stemming applies on the following:
Lemmatization: Lemmatization is the process in which the affixes of words are removed and the words are converted to their base form with meaning.
Lemmatization makes sure that lemma is a word with meaning.
For example:
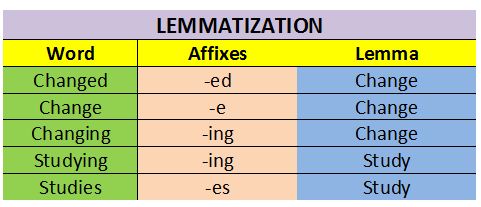
Difference between stemming and lemmatization can be summarized by this example:
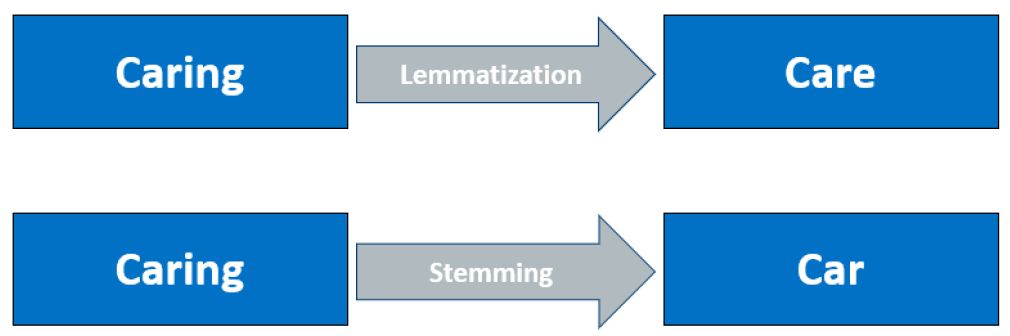
Finally, We reduced Given Text (Corpus) into Normalized Text.
- raj, vijay, best, friends
- play, together, with, other, friends
- raj, like, play, football, but, vijay, prefer, play, online, games
- raj, want, be, footballer
- vijay, want, become, online, gamer
Now it is time to convert the tokens into numbers. For this, we would use the Bag of Words algorithm. Click here to know more about Bag of Word algorithm >>