Bag of Words (BoW)
Bag of Words is a NLP model which helps in extracting features from textual data. It converts text sentences into numeric vectors by returing the unique words along with its number of occurences.
Bag of Words creates a set of vectors containing the count of word occurrences in the document.
Bag of words gives us two things:
1. A vocabulary of words for the corpus
2. The frequency of these words (number of times it has occurred in the whole corpus).
Steps to implement bag of words algorithm:
- Text Normalisation: Reduce the corpus into normal form.
- Create Dictionary: Make a list of all the unique words occurring in the corpus.
- Create document vectors: For each document in the corpus, find out how many times the word from the unique list of words has occurred.
- Repeat the Step 3 for all the documents.
Let us go through all the steps with an example:
Document 1: Aman and Anil are stressed.
Document 2: Aman went to a therapist.
Document 3: Anil went to download a health chatbot.
1. Text Normalisation
After text normalisation, the text becomes:
Document 1: [aman, and, anil, are, stressed]
Document 2: [aman, went, to, a, therapist]
Document 3: [anil, went, to, download, a, health, chatbot]
Note: Note that no tokens have been removed in the stopwords removal step. It is because we have very little data and since the frequency of all the words is almost the same, no word can be said to have lesser value than the other.
2. Create Dictionary
create a dictionary means make a list of all the unique words occurring in all three documents.

3. Create document vectors
In this step, the vocabulary is written in the top row. Now, for each word in the document, if it matches with the vocabulary, put a 1 under it. If the same word appears again, increment the previous value by 1. And if the word does not occur in that document, put a 0 under it.

Since in the first document, we have words: aman, and, anil, are, stressed. So, all these words get a value of 1 and rest of the words get a 0 value.
4. Create document vectors for all the documents
Repeat step 3 for all the documents to get vectors.
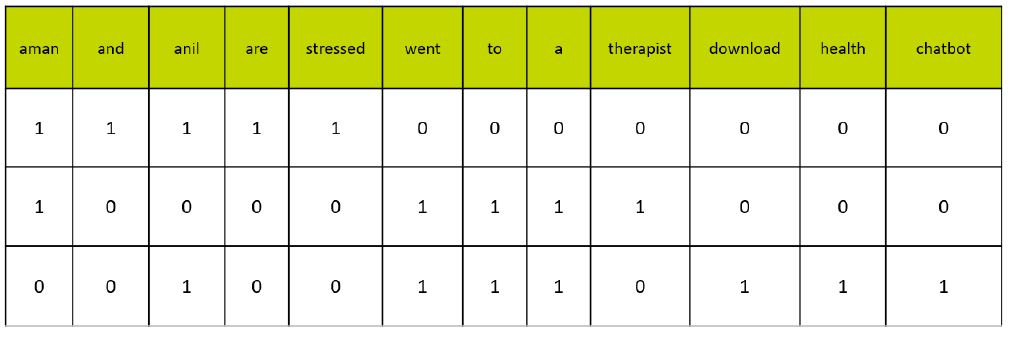
In this table, the header row contains the vocabulary of the corpus and three rows correspond to three different documents. Take a look at this table and analyse the positioning of 0s and 1s in it.
Finally, this gives us the document vector table for our corpus. But the tokens have still not converted to numbers.
This leads us to the final steps of our algorithm: TF-IDF (Term Frequency & Inverse Document Frequency).
View More