Q.A. on NLP
Q. What is a Chabot?
A. Click here to know more >>
Q. What is the full form of NLP?
A. Natural Language Processing
Q. Explain Syntax and Semantics While working with NLP.
A. Syntax: Syntax refers to the grammatical structure of a sentence.
Semantics: It refers to the meaning of the sentence.Click here to know more >>
Q. Define the following:
● Stemming
● Lemmatization
A. Click here to know more >>
Q. What is the difference between stemming and lemmatization?
A. Click here to know more >>
Q. What is the difference between stems and lemmas?
A. Stems is root word generated by stemming process. Whereas Lemmas is root word generated by lemmatization process.
Q. What will be the output of the word "studies", if we do the following:
a) Lemmatization
b) Stemming
A. a) Lemmatization - study
b) Stemming - studi
Q. What is the full form of TFIDF?
A. TFIDF stands for Term Frequency and Inverse Document Frequency
Q. What is meant by a dictionary in NLP?
A. Dictionary in NLP means a list of all the unique words occurring in the corpus. Some words are repeated in all documents, they are all written just once which known as dictionary. Click here to know more >>
Q. Which package is used for Natural Language Processing in Python programming?
A. Natural Language Toolkit (NLTK) is one of the leading platforms for building Python programs that can work with human language data. Click here to know more >>
Q. What is a document vector table?
A. Document Vector Table is used while implementing Bag of Words algorithm. Document Vector Table is a table containing the frequency of each word of the vocabulary in each document. Click here to know more >>
Q. What do you mean by document vectors?
A. Document Vector contains the frequency of each word of the vocabulary in a particular document. Click here to know more >>
Q. What do you mean by corpus?
A. A corpus can be defined as a collection of entire text of all documents in a dataset. Click here to know more >>
Q. What are the types of data used for Natural Language Processing applications?
A. Natural Language Processing applications are used written words and spoken words which humans use in their daily lives.
Q. Differentiate between a script-bot and a smart-bot. (Any 2 differences)
A. Click here to know more >>
Q. Give an example of the following:
Multiple meanings of a word
Perfect syntax, no meaning
A. Click here to know more >>
Q. Which words in a corpus have the highest values and which ones have the least values?
A. Stop words like - and, this, is, the, to, etc. have highest values in a corpus.
But these words do not talk about the corpus at all. Hence, these words are removed at the pre-processing stage.
Rare or valuable words occur the least values but add the most importance to the corpus.
Q. Does the vocabulary of a corpus remain the same before and after text normalization? Why?
A. No, the vocabulary of a corpus does not remain the same before and after text normalization. Because –
● In normalization the text is normalized through various steps and is lowered to minimum vocabulary.
● In normalization Stop words, Special Characters and Numbers are removed.
● In stemming, the affixes of words are removed and the words are converted to their base form.
So, after normalization, we get the reduced vocabulary.
Q. What is the significance of converting the text into a common case?
A. In Text Normalization, we undergo several steps to normalize the text to a lower level.
1. Sentence Segmentation
2. Tokenisation
3. Removing Stopwords, Special Characters and Numbers
4. Converting text to a common case
5. Stemming/Lemmatization Click here to know more >>
Q. Mention some applications of Natural Language Processing.
A. Natural Language Processing Applications -
● Sentiment Analysis.
● Chatbots & Virtual Assistants.
● Text Classification.
● Text Extraction.
● Machine Translation
● Text Summarization
● Market Intelligence
● Auto-Correct Click here to know more >>
Q. Explain the concept of Bag of Words (BoW).
A. Bag of Words is a NLP model which helps in extracting features out of the text which can be helpful in machine learning algorithms.
Bag of Words just creates a set of vectors containing the count of word occurrences in the document.
Bag of words gives us two things:
1. A vocabulary of words for the corpus
2. The frequency of these words (number of times it has occurred in the whole corpus). Click here to know more >>
Q. What are stop words? Explain with the help of examples.
A. Stopwords are the words which occur very frequently in the corpus but do not add any value to it. eg. - a, an, and, are, as, for, it, is, into, in, if, on, or, such, the, there, to etc. Hence, to make it easier for the computer to focus on meaningful terms, these words are removed. Click here to know more >>
Q. Differentiate between Human Language and Computer Language.
A. Humans communicate through language which we process all the time. Our brain keeps on processing the sounds that it hears around itself and tries to make sense out of them all the time.
On the other hand, the computer understands the language of numbers. Everything that is sent to the machine has to be converted to numbers. And while typing, if a single mistake is made, the computer throws an error and does not process that part. The communications made by the machines are very basic and simple.
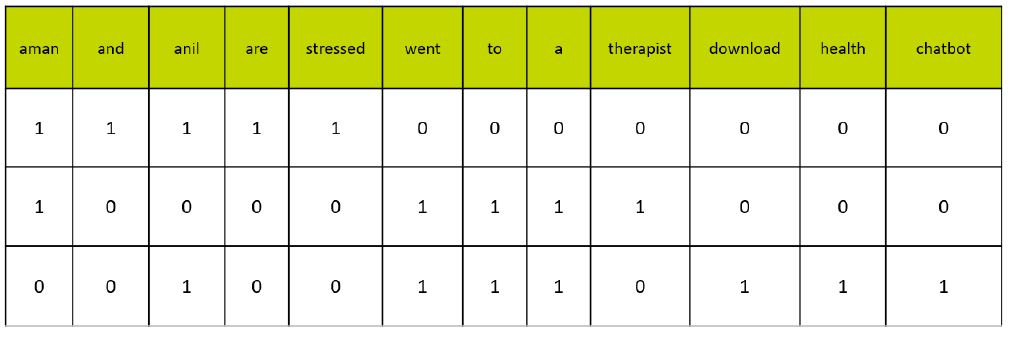
Q. Create a document vector table for the given corpus:
Document 1: Aman and Anil are stressed.
Document 2: Aman went to a therapist.
Document 3: Anil went to download a health chatbot
A.
Q. Explain how AI can play a role in sentiment analysis of human beings?
A. The goal of sentiment analysis is to identify sentiment among several posts or even in the same post where emotion is not always explicitly expressed.
Companies use Natural Language Processing applications, such as sentiment analysis, to identify opinions and sentiment online to help them understand what customers think about their products and services.(i.e., “I love the new iPhone” and, a few lines later “But sometimes it doesn’t work well” where the person is still talking about the iPhone) Click here to know more >>
Q. Why are human languages complicated for a computer to understand? Explain.
A. Click here to know more >>
Q. What are the steps of text Normalization? Explain them in brief.
A. Click here to know more >>
Q. Normalize the given text and comment on the vocabulary before and after the normalization:
Raj and Vijay are best friends. They play together with other friends. Raj likes to play football but Vijay prefers to play online games. Raj wants to be a footballer. Vijay wants to become an online gamer.
A. Click here to know more >>
Q. How many tokens are there in the sentence given below:
Raj and Vijay are best friends. They play together with other friends. Raj likes to play football but Vijay prefers to play online games. Raj wants to be a footballer. Vijay wants to become an online gamer.
A. 42 tokens
Q. Identify any four stopwords in the sentence given below:
Raj and Vijay are best friends. They play together with other friends. Raj likes to play football but Vijay prefers to play online games. Raj wants to be a footballer. Vijay wants to become an online gamer.
A. and, are, to, be, a, an, etc.