Unsupervised Learning
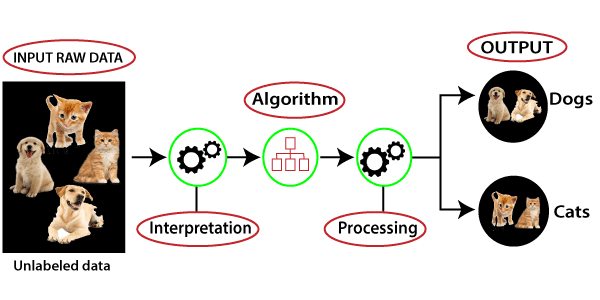
In this type of learning, the neural network is only provided with inputs. It doesn’t receive any information regarding the output. The system by itself evaluates and finds out how different elements are related to it.

For example - A child learning on his own without any supervision and trying to discover ways and techniques.
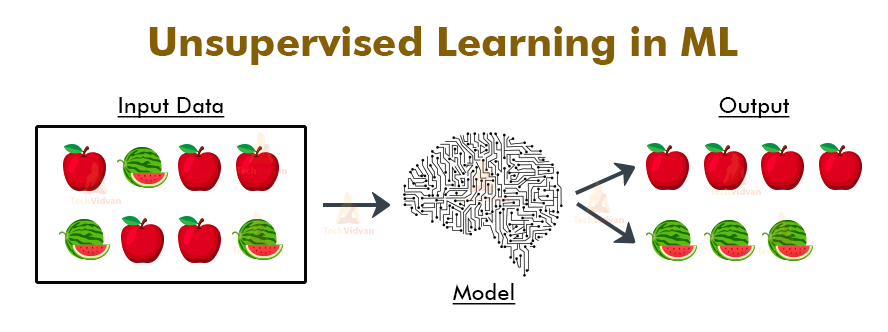
In unsupervised machine learning, the machine is trained using the unlabeled dataset, and the machine predicts the output without any supervision.
The large amount of unlabelled data is given to the machine and then it finds out some rules understand the properties of the data and try to make group, cluster, and/or organize the data in a way such that it can make some sense of the newly organized data.
or
Applications of Unsupervised Machine Learning
- Recommendation applications for different web applications and e-commerce websites uses the watch history from user's account that you have yet to see, a recommender system can see this relationship in the data and prompt you with such a suggestion.
- Analyze bank data for suspicious-looking transactions.
Models based on Unsupervised Learning
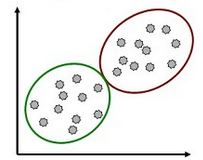
1. Clustering Model: This model is based on Unsupervised Learning that uses unlabelled data (Random data) to find the inherent groups from the data. It is a way to group the objects into a cluster such that the objects with the most similarities remain in one group and have fewer or no similarities with the objects of other groups. It works on discrete dataset.
An example of the clustering algorithm is grouping the customers by their purchasing behaviour.
or
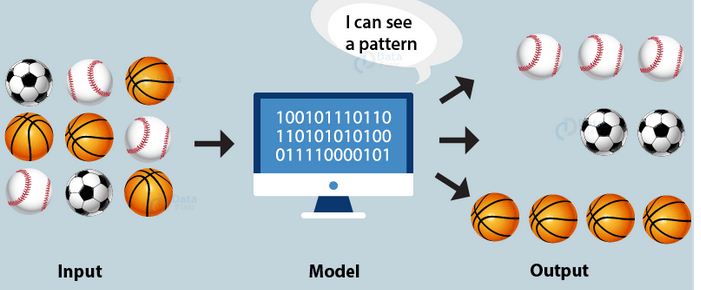
In Clustering AI model, the machine generates its own rules or algorithms to differentiate amongst the given dataset to achieve the pre-decided goal. The data feed to such a model is usually unlabelled or random and thus the developer feeds in the data directly into the machine and instructs it to build its own algorithm. The machine then finds out patterns or trends out of the training dataset and clusters the ones which follow the same pattern. The output rules might be very different to what was expected as the machine has its own way of recognising patterns.
For example, if you have a random data of stray dogs which live in your locality, since you are unable to find any meaningful pattern amongst them, you would feed their data into the clustering algorithm. The algorithm would then analyse the data and divide them into clusters according to their similarities based on the trends noticed. The clusters are then given as the output.
2. Association Model: It is an unsupervised learning method that is used to find interesting relationships between variables from the database.

Based on the purchase pattern of customers A and B, we can predict that there is high probability that any customer x who buys bread will most probably buy butter. Therefore, such meaningful associations can be useful to recommend items to customers. This is called Association Rule.
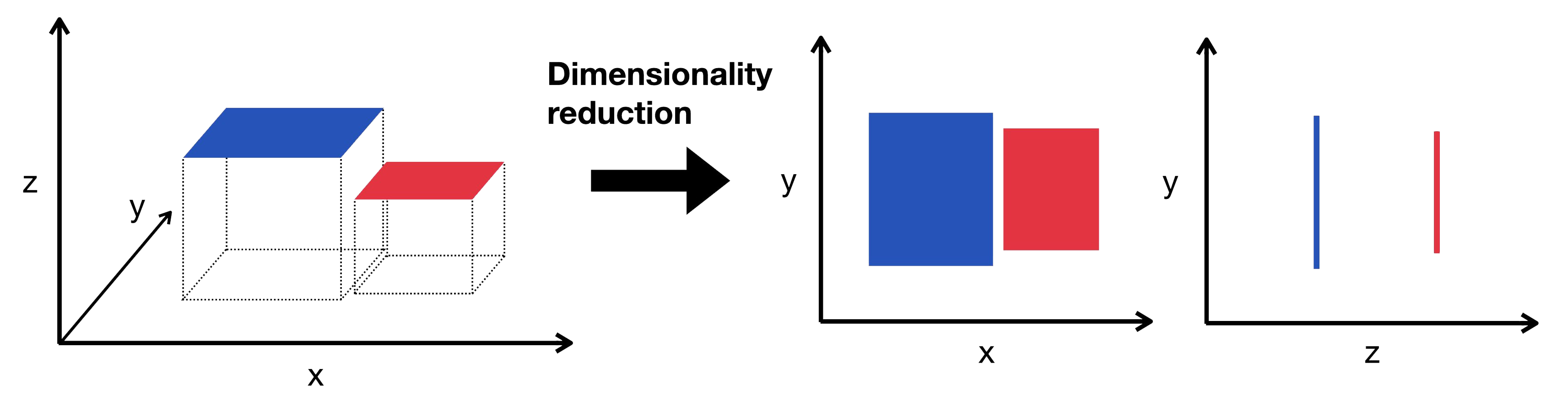
3. Dimensionality Reduce Model: There are n number of dimensions in the world, but we humans can only understand upto 3D (3 dimensions). Therefore, we may need to represent it in lesser dimensions (number of variables) for visualisation purposes. Thus, Dimensionality Reduce Model is required. It is an Unsupervised Learning that uses techniques for reducing the dimensions (number of input variables) in training data while retaining its sense and meaning.