REGRESSION AI MODEL
This model is based on Supervised Learning that uses labelled data to predict continuous output variables. It works with continuous data.
Some examples are market trends, weather prediction, salary of employees, etc.
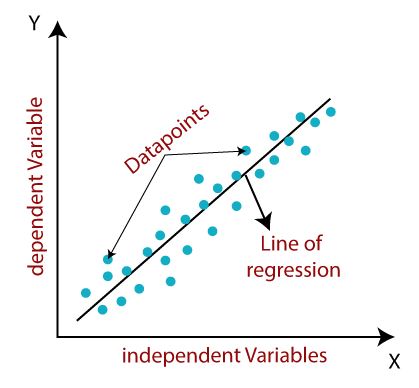
In regression, the algorithm generates a mapping function from the given data, represented by the solid line. The green dots shown in the graph are the data values and the solid line here represents the mapping done for them. With the help of this mapping function, we can predict the future data.
For example, if we want to predict the salary of an employee, we can use his past salaries as training data and can predict his next salary.
CLASSIFICATION AI MODEL
This model is based on Supervised Learning that uses labelled data to solve the classification problems in which the output variable is categorical, such as "Yes" or No, Male or Female, Red or Blue, etc. The classification algorithms predict the categories present in the dataset. It works with non-continuous data or discrete dataset.
Some real-world examples of classification algorithms are Spam Detection, Email filtering, etc.
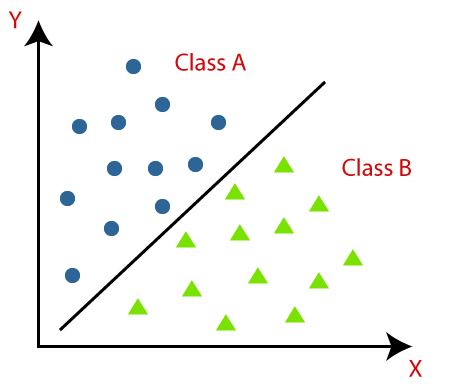
In classification, the model classifies datasets according to the rules given to it. Usually the dataset used for classification are labelled and the data then gets sorted according to their labelling. Testing data is then classified as one of the labels of the training dataset.
For example, If we want to train a model to identify if an image is of a guitar or a piano, we need to train it with multiple images of both guitar and piano along with their labels. The machine will then classify images on the basis of the labels and predict the correct label for testing data.
CLUSTERING AI MODEL
This model is based on Unsupervised Learning that uses unlabelled data (Random data) to find the inherent groups from the data. It is a way to group the objects into a cluster such that the objects with the most similarities remain in one group and have fewer or no similarities with the objects of other groups. It works on discrete dataset.
An example of the clustering algorithm is grouping the customers by their purchasing behaviour.
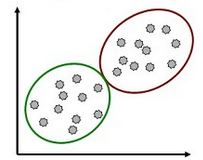
or
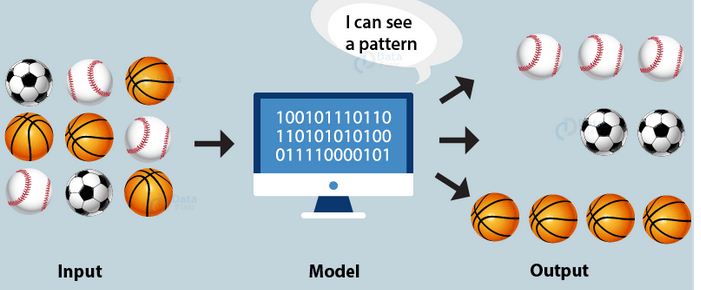
In Clustering AI model, the machine generates its own rules or algorithms to differentiate amongst the given dataset to achieve the pre-decided goal. The data feed to such a model is usually unlabelled or random and thus the developer feeds in the data directly into the machine and instructs it to build its own algorithm. The machine then finds out patterns or trends out of the training dataset and clusters the ones which follow the same pattern. The output rules might be very different to what was expected as the machine has its own way of recognising patterns.
For example, if you have a random data of stray dogs which live in your locality, since you are unable to find any meaningful pattern amongst them, you would feed their data into the clustering algorithm. The algorithm would then analyse the data and divide them into clusters according to their similarities based on the trends noticed. The clusters are then given as the output.